Catering For The Disabled Surfer: A Case Study In Web Site Navigation For Disabled Students
ABSTRACT
Speech recognition can enable some people to perform daily living tasks without assistance. For others, such as the growing number of professionals afflicted with repetitive stress syndrome, speech recognition represents a means of getting or keeping employment. Thus, speech recognition as a navigation aid is a key in solving the dilemma of a subset of disabled surfers. This paper reviews the technologies currently available for speech interaction with computers and suggests how the future of web navigation may benefit from these technologies. The paper also discusses the results obtained from evaluation of a prototype disabled website by local health board officials which indicated a positive response to the Voice Navigable website and aided recommendations such as adding a range of vocal speeds, accents and characters.
INTRODUCTION
Since the computer as we know it was first developed, man has dreamt of systems that can be operated by voice command. Science fiction has portrayed a future where users communicate with computers by voice, and generations have grown up expecting a new dawn whereby we speak and the computer speaks back. The days of communicating naturally with computers by speech, however, are not so far off. Recent technological developments have led to a new way of thinking about how we should interact with computers in general, with the development of the XML specification and the use of XML to develop applications for many types of data. In particular, Voice XML and Speech Application Language Tags (SALT) (http://www.saltforum.org/) are technologies that could revolutionise navigation of computer systems. Speech technology seems an ideal complement to web appliances. Advances in speech processing have already yielded for users a far more natural sounding voice reading web information. The incorporation of speech recognition can be an important source of user acceptance of any system. Teaching through the use of web pages has provided an alternative way of learning for many people including those who have a disability. A severely physically disabled student may find it advantageous to study at home, but if the principal teaching medium is the web and the student is unable to independently navigate the pages of the site, then a barrier to learning exists. The provision of services such as audio transcription may depend on the number of students who require the service, and providing 100 students per year with an audio recording of the same course does have advantage in scale compared to a situation where there are only a few students in a course.
This paper reviews the technologies currently available for speech interaction with computers and suggests how the future of web navigation may benefit from these technologies. The paper also discusses the results obtained from evaluation of a voice navigatable website aimed at disabled users.
DISABILITY
Speech recognition is being used to give some severely disabled people a means of remote control of their environments - a way to choose independently among several activities such as watching television and listening to the radio. For people with physical disabilities affecting the use of their hands, productivity is far more personal. Speech recognition can enable some people to perform daily living tasks without assistance. For others, such as the growing number of professionals afflicted with Repetitive Stress Syndrome (RSI), speech recognition represents a means of getting or keeping employment.
Reasons that people with a disability use voice recognition include limited use of hands, difficulty with spelling, inability to touch type, and need of a fast way of working. Therefore a user needing to work "hands-free" will need a reliable method of controlling menus: a means of moving and clicking the mouse using voice commands and a correction mechanism that works completely by voice. Users with spelling difficulties need predictive correction, a text to speech feature to help with proofreading, and a facility to "play back" what was dictated (i.e. their voice). People who wish to speed up typing are likely to be most interested in speed of recognition and easy correction using the mouse.
Many visually impaired users are attracted to the idea of operating their computer by voice, necessitated either by keyboarding difficulties or lack of touch-typing proficiency. Voice in/Voice out is the use of a computer with voice recognition as a means of information input, combined with synthetic speech that enables the user to know what is on the computer screen. Many problems are inherent in using voice recognition with speech output. The main problems are:
- Hearing the words or phrases echoed back is often not enough for the user to be sure there are no errors in the recognition or formatting of the text.
- It is very easy to become disoriented when a command has been misrecognised and one is suddenly taken somewhere unexpected. This can be frustrating, and at worst disastrous [Peissner01].
If the programs can be used without keyboard or mouse they are said to work 'hands-free'. The different voice recognition packages available range from complete hands-free use to merely limited use without access to keyboard or mouse. The different screen-reader functions such as 'say line' or 'spell word', which would usually involve a key combination, are accessed by verbal commands that may or may not be already set up for you. One of the primary challenges of designing applications for people with disabilities is that each group has unique requirements and concerns. Motor impaired individuals, for example, range from quadriplegics to people with Repetitive Stress Syndrome (RSI). The groups who have been the primary focus of speech recognition application development in the past are people with motor and visual impairments. Research systems have been designed for people with mild cognitive impairments and individuals with speech and hearing impairments.
NATURAL HUMAN COMPUTER INTERACTION
When we use a computer system to perform a certain task, the computer system acts both as a tool and as a partner in communication. The information that is being exchanged between the user and the system during task performance can be represented in different forms, or modalities, using a variety of different input/output devices. A user interface is that component of any product, service, or application that interacts directly with the human user. The job of the interface is twofold. First, it must present information to the user - information about the task at hand as well as information about the interface itself. Second, it must accept input from the user - input in the form of commands or operations that allow the user to control the application [Ballentine99].
A spoken user interface is one in which both machine presentation and user inputs take the form of human speech. Speech replaces the video display, indicator lights, buttons, and knobs of the more traditional user interfaces. The machine presents output through digitised or synthesised speech - in effect, "reciting" information to the user - and accepts and interprets spoken user input through the use of speech recognition technology. Interactive speech systems represent one step towards fully natural communication with computer systems. Dialogue-based applications involve human-machine communication. Most naturally this involves spoken language, but it also includes interaction using keyboards. Typical potential applications include [Rosson02]:
- question-answering systems, where natural language is used to query a database;
- automated customer service over the telephone;
- tutoring systems, where the machine interacts with a student;
- spoken language control of a machine; and
- general cooperative problem-solving systems
SPEECH RECOGNITION
Until recently, the World Wide Web has relied exclusively on visual interfaces to deliver information and services to users via computers equipped with a monitor, keyboard, and pointing device. In doing so, a huge potential customer base has been ignored: people who (due to time, location, and/or cost constraints) do not have access to a computer. Speech recognition, or speech-to-text, involves capturing and digitising sound waves, converting them to basic language units or phonemes, constructing words from phonemes, and contextually analysing the words to ensure correct spelling for words that sound alike (such as write and right).
Figure 1 illustrates this high-level description of the process.
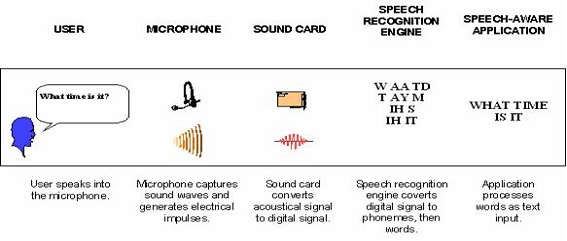
Figure 1 : Speech Recognition Process Flow [Lai00]
Recognisers - also referred to as speech recognition engines - are the software drivers that convert the acoustical signal to a digital signal and deliver recognised speech as text to the application. Most recognisers support continuous speech, meaning you can speak naturally into a microphone at the speed of most conversations. Isolated or discrete speech recognisers require the user to pause after each word, and are currently being replaced by continuous speech engines. Speech recognition technology enables developers to include the following features in their applications [Terken02]:
- Hands-free computing can be used an alternative to the keyboard, or in environments where a keyboard is impractical (e.g., small mobile devices, AutoPCs, or in mobile phones).
- A more "human" computer, one the user can talk to, may make educational and entertainment applications seem more friendly and realistic.
- Voice responses to message boxes and wizard screens can easily be designed into an application.
- Streamlined access to application controls and large lists enables a user to speak any one item from a list or any command from a potentially huge set of commands without having to navigate through several dialog boxes or cascading menus.
- Speech-activated macros let a user speak a natural word or phrase rather than use the keyboard or a command to activate a macro. For example, saying "Spell check the paragraph" is easier for most users to remember than the CTRL+F5 key combination.
- Situational dialogs are possible between the user and the computer in which the computer asks the user, "What do you want to do?" and branches according to the reply. For example, the user might reply, "I want to book a flight from New York to Boston". The computer analyses the reply, clarifies any ambiguous words ("Did you say New York?"), and then asks for any information that the user did not supply, such as "What day and time do you want to leave?"
SPEECH NAVIGATION
VoiceXML, developed in 1999, is led by IBM, Motorola, AT&T and Lucent Technologies [Philips01]. It was originally designed to allow applications to be accessed by telephone. Efforts are underway to add the capability to voice-enable applications that are accessed using the Web. VoiceXML is an XML (Extensible Mark-up Language) language for writing Web pages you interact with by listening to spoken prompts and jingles, and control by means of spoken input. HTML (Hypertext Mark-up Language) was designed for visual Web pages and lacks the control over the user-application interaction that is needed for a speech-based interface. With speech you can only hear one thing at a time. VoiceXML has been carefully designed to give authors full control over spoken dialogue between the user and the application. The application and user take it in turns to speak: the application prompts the user, and the user in turn responds [Lucas00].
Interactive Voice Response (IVR) applications make it possible to get stock quotes or check account balances without talking to a person. Nevertheless, most IVR software and hardware is proprietary, which has slowed the market by making it impossible for software developers to build an application that runs on multiple platforms, and users are often stuck with an expensive product from one vendor. A group led in part by Microsoft & Speechworks International, known as the SALT Forum, short for Speech Application Language Tags, released the first public specification of its technology [Jurvis02]. When completed, the technology would allow developers to add speech "tags" to web applications written in XML and HTML, allowing those applications to be controlled through voice commends rather than a mouse or a keyboard.
SALT is based on a unique structure combining a core language specification with device-specific capability profiles, making it suitable for a wide spectrum of multimodal and telephony platforms throughout the world. To speed its adoption, SALT is harmonious with today's popular speech engines and Web development tools. It also offers suggestions about how developers might consider using the technology to voice-enable Web applications, creating what are known as "multimodal" programs that can be controlled by both voice and traditional input methods. The SALT specification is also designed for applications that do not have a visual user interface, such as those accessed by telephone.
A SPEECH NAVIGABLE DISABILITY WEBSITE
In order to demonstrate Web site navigation via voice, a disability Web site was developed enabling voice interaction with the site. The technology selected was Interactive Speech Technology's (http://www.interactivespeech.com) Voice Navigation Module. The site was named disABILITY Interactive consisting of pages that were vocally linked and therefore navigable by speech. Interactive Speech Technologies provided a basis for incorporating voice navigation technology to Macromedia Flash movies, 3D animations and regular HTML pages. Along with MakeWord, the voice navigation module enabled voice commands throughout the Web site.
Ergonomics and navigability are important issues when designing Web sites. Voice navigation answers web-surfers needs in terms of interactivity and conviviality. In developing the visual presentation style (see Figure 5), we sought to satisfy the following desirable user requirements:
- Male/female voice recognition
- BrowseAloud - for dyslexic people, visually impaired
- Effective combination of colours suitable for people with colour blindness
- Large text
- Pages kept short - does not overload user's short-term memory
- Vocal navigation - hands free use, reliable method of controlling menus
- Instructions via voice recorder
MakeWord (http://www.interactivespeech.com/en/ressources.htm) (Figure 2) allows the definition of vocal links for each HTML page. The vocal commands are then saved in an IAS file. Usually the voice commands correspond to hyperlinks that exist in the HTML file. However, this is not always the case. There can be hyperlinks in the HTML file with no voice-command associated. With those links, the URL and target cannot be modified because they are defined in the HTML file. There can be pure voice-commands (not created from a HTML hyperlink), and, finally links with neither a HTML hyperlink associated nor a voice model. Figure 2 illustrates how links are shown once voice is added.
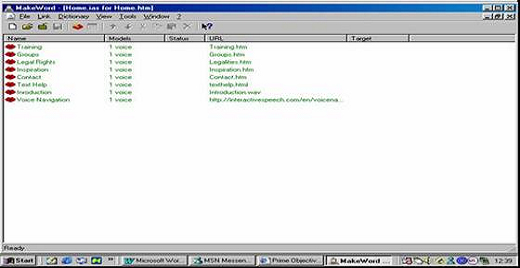
Figure 2 : Makeword - Hyperlinks now voice activated
EMBED and OBJECT tags must be placed in each vocal HTML page in order to transmit to the visitor's module the possible commands. The EMBED tag is aimed at Netscape, the OBJECT tag at Internet Explorer. This is what is called "defining the path for the dictionaries".
| <OBJECT id=VoiceNav classid="CLSID:4CD9F50C-280D-11D5-9690-0050BAE15BF6" height=0 width=0> <PARAM name=Dictionary value="Home.ias"> </OBJECT> |
Figure 3 : The OBJECT Tag
In Figure 3 the home.ias parameter to Dictionary indicates the name and location of the IAS(InterActive Speech) dictionary associated to the HTML page. It is equivalent to the SRC attribute in the EMBED tag.
| <SCRIPT type="text/javascript"> if (navigator.appName.indexOf("Internet Explorer")<0) document.writeln('<EMBED src="Home.ias" type="application/x-NavigationByVoice" width=2 height=2>'); </SCRIPT> |
Figure 4 : The EMBED tag
In Figure 4, Home.ias indicates the location and name of the IAS file. Type=application/x-navigationByVoice indicates to the browser the plugin (here, x-NavigationByVoice) to which the IAS file must be sent.
When a visitor of the website arrives on the page, his/her browser downloads the text and pictures of that page. At the same time, the voice-navigation plugin (shown on the right-hand side of Figure 5) automatically downloads the .IAS file and then waits until the user pronounces one of the vocal links contained in this .IAS file. When this happens, the plugin asks the browser to 'jump' to the desired page.
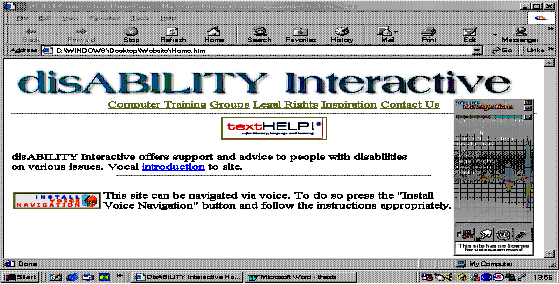
Figure 5 : Voice Navigable disABILITY Interactive Web site
The voice navigation system is based on an acoustic comparison between, on one hand, the voice link pronounced by the visitor when visiting a given page and, on the other hand, the possible voice commands available on this page. These possible voice commands are defined and recorded by the website designer (see Figure 6).
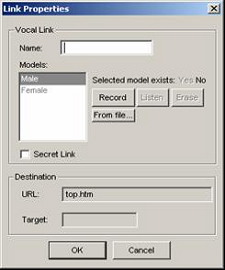
Figure 6 : Recording vocal links
Human Factors of command-and-control
Many people who use command-and-control applications view speech recognition as a facet of the machine they are operating. For them, the role of speech is to translate verbal commands directly into action. There is often little tolerance of error and no patience for slow throughput or efficiency. Command-and-control systems must be simple and easy to use, and must possess vocabulary that is easy to remember and access. Environment control systems for people with disabilities require tailoring to the needs of each individual. For people with severe speech problems this may require careful selection of vocabulary to enhance word differentiation within capabilities of the individual.
![]()
Figure 7 : BrowseAloud/TextHelp!
Browse Aloud (Figure 7) is an add-in for Internet Explorer that allows web pages to be read with highlighting in-page. The user can download textHelp! from the home page. The user can subsequently use this on any Web site that they encounter. The BrowseAloud settings can be altered by way of speed, pitch, volume, accent, and gender of the speaker to cater for all types of users. Pre-recorded audio files enable the user to hear an introduction to the Web site, information about other disability groups and so forth. It adds value by way of developing interactivity between the user and the Web site. The developer's voice is recorded using the Sound Recorder and linked appropriately within the HTML body with code such as Vocal <A HREF="Introduction.wav">introduction</A>.
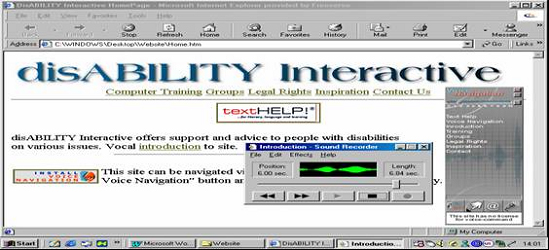
Figure 8 : disABILITY Interactive Home Page with prerecorded audio files
Figure 8 illustrates how the Home Page of disABILITY Interactive looks with the Sound Recorder operating.
EVALUATION
In the initial prototype, the commands were thought to be chosen and recorded with great care to guarantee a unique Voice Navigation experience to all visitors, however the experience in the field was somewhat different. Over a period of two weeks of use in the community at various nursing homes, hospitals, and senior citizen groups, the findings were as follows:
- Ambiguous Commands. Some of the commands were not different enough. The group of voice commands should not contain words that are too close together. The choice of words afterwards was always checked with MakeWord's tester.
- Length of Commands. Commands of two or three words were preferred to shorter one word commands.
- Opposite Sex Voice Commands. Findings showed that male voice commands had a higher miss ration than female voice commands. This was discovered to be due to the fact that all commands had been input by a female. When commands were mirrored by a male voice input, the miss ratio diminished. Additional voices could also be useful for sites aimed at children.
- Noise Control. Some of the early commands did not perform quite as well as later commands. This was probably due to background noise in the busy undergraduate laboratory that was used for recording. Later version of the site featured voice commands that were recorded in a quieter environment, with a good-quality microphone and sound card. The recording of the command was always checked just after recording it to eradicate any interference. MakeWord's integrated voice-commands tester ensures that the voice commands that have been chosen and recorded are distinct enough. The score 2.43 is the criteria to decide whether or not the recogniser is sure. A score above a threshold of 0.20 ensures that a word is recognisable. The probability of a confusion of the speech recogniser increases when there are more active words at the same time. However, 15-20 words can be active at a time without any problem (if those words are chosen and recorded correctly).
In addition, during the iterative testing and evaluation, a number of issues arose, such as restrictions in the actual range of voices and lack of support for speech impediments. Therefore, main priorities in the near future are:
- incorporation of voices that have accents, different speeds, and different tones;
- lateral development with Microsoft's Speech Application Tags; and
- future development of 'hands busy/eyes busy' environment scenario.
RELATED WORK
Software packages that can process speech have been around for some time and include speech recognition and text-to-speech applications. Some of the speech recognition products that are available now are IBM's ViaVoice [IBM02], CSLU [CSLU02] and [Nuance02]. However, none of these technologies are designed for incorporating into website navigation. In addition, to date most Interactive Voice Response (IVR) software and hardware is proprietary, which has slowed the market by making it impossible for software developers to build an application that runs on multiple platforms.
CONCLUSION
What makes interactive speech systems particularly interesting at the present time is that they have recently become commercially available in their most versatile and natural form, i.e. real-time systems that understand speaker-independent continuous speech. Acceptable-quality speech synthesis in several languages has already been in existence for some time. Our system provides a facility that enables users with different forms of disability to navigate the World Wide Web in a variety of ways. It demonstrates that the concept of Voice Navigation through the World Wide Web holds much potential for computer users with disabilities, office staff and the mobile Information Technology Market.
REFERENCES
[Ballentine99] Ballentine, B., Morgan, D. How to Build a Speech Recognition Application. A Style Guide for Telephony Dialogues, CA: Enterprise Integration Group, Inc., San Ramon. 1999
[Jurvis02] Jurvis, Jeff. Speak Up: Speech I/O for the Wireless Web. XML and Web Services Magazine, http://www.fawcette.com/xmlmag/2002_06/magazine/columns/xmlunplugged/, June 2002
[Lai00] Lai, J.,Wood, D., Considine, M. The Effects of Task Conditions on the Comprehensibility of Synthetic Speech. ACM SIG CHI 2000 Conference Proceedings (pp. 321 - 329), 2000.
[Lucas00] Lucas, B. 'VoiceXML for Web-based distributed applications'. Communications of the ACM: New York, Vol. 43, pp53-57, 2000
[Peissner01] Peissner, M., Heidmann, F. and Ziegler, J. Simulating recognition errors in speech user interface prototyping, In M.J. Smith, G. Salvendy, D. Harris, and R.J. Koubek (Eds), "Usability Evaluation and Interface Design", Lawrence Erlbaum Associates, Inc., Mahwah, NJ, pp. 233-237, 2001.
[Phillips01] Phillips, Lee. VoiceXML: The new standard in Web Telephony, http://www.webreview.com, 2001
[Rosson02] Rosson, M. B. and Carroll, J. M. Usability Engineering: Scenario-Based Development of Human-Computer Interaction. Morgan Kaufmann, San Francisco, 2002.
[Java02] Sun Microsystems, Inc. Java Speech API Programmer's Guide (version 1.0), Available at http://java.sun.com/products/java-media/speech/.
[Terken00] Terken, J. and Beers, M. Usability Evaluation of Voice Operated Information Systems: Analysis of Dialogues with Real Customers, presented at CHI 2000 Workshop on Natural Language Interfaces, The Hague, Netherlands, April 2000.